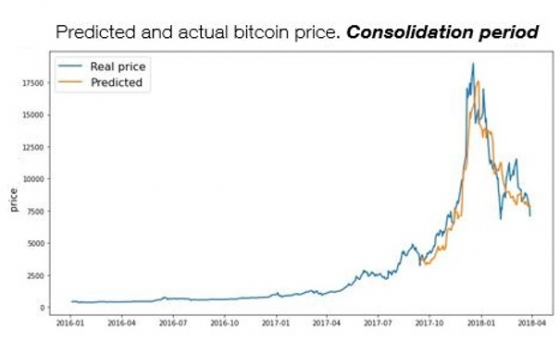
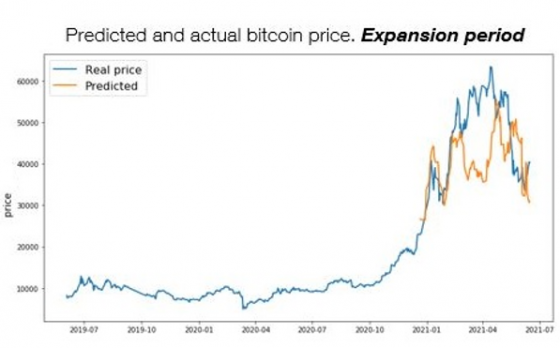
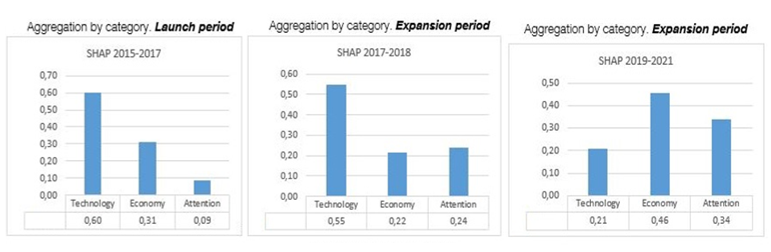
References
Abbasimehr, H., Shabani, M., & Yousefi, M. (2020). An optimized model using LSTM network for demand forecasting. Computers & industrial engineering, 143, 106435.
Albanesi, S., & Vamossy, D. F. (2019). Predicting consumer default: A deep learning approach (No. w26165). National Bureau of Economic Research.
Alonso, A., & Carbó, J. M. (2022). Accuracy of explanations of machine learning models for credit decisions. Documentos de Trabajo/Banco de España, 2222.
Chen, W., Xu, H., Jia, L., & Gao, Y. (2021). Machine learning model for Bitcoin exchange rate prediction using economic and technology determinants. International Journal of Forecasting, 37(1), 28-43.
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8), 1735-1780.
Lundberg, S.M. and S.I. Lee (2017). “A unified approach to interpreting model predictions” Advances in neural information processing systems, pp. 4765-4774.
Molnar, C. (2020). Interpretable machine learning. Lulu. com.