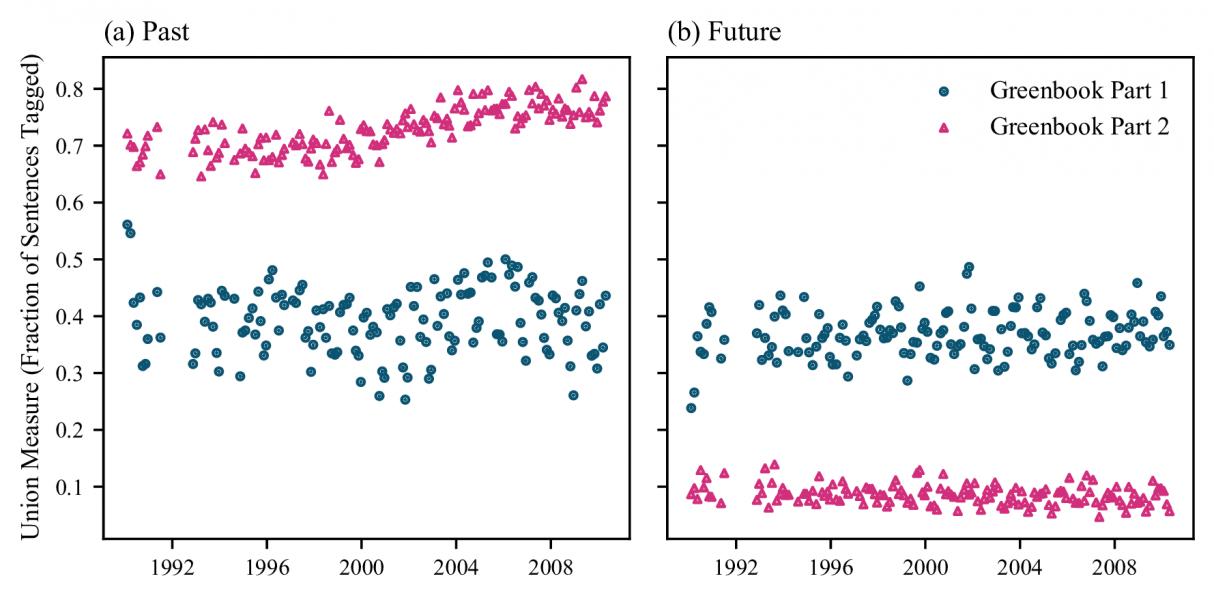
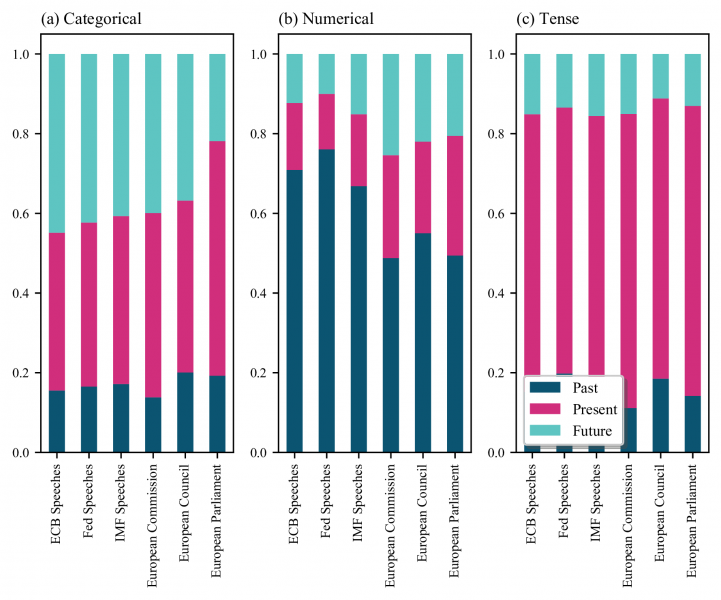
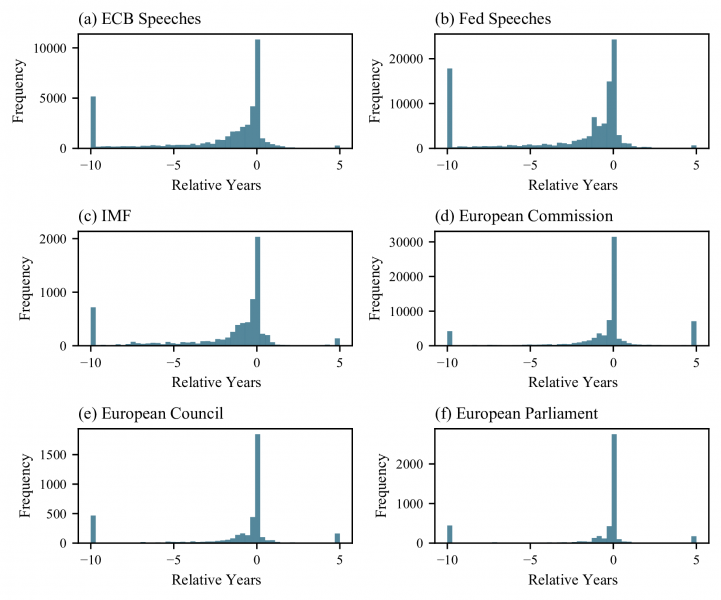
References
Apel, Mikael, Blix Grimaldi, Marianna and Hull, Isaiah, (2022), “How Much Information Do Monetary Policy Committees Disclose? Evidence from the FOMC’s Minutes and Transcripts”, Journal of Money, Credit and Banking, 54, issue 5, p. 1459-1490.
Azqueta-Gavaldon, Andres, (2017), “Developing news-based Economic Policy Uncertainty index with unsupervised machine learning”, Economics Letters, 158, issue C, p. 47-50.
Blei, David M., Ng, Andrew Y. and Jordan, Michael I. (2003). “Latent Dirichlet Allocation”. Journal of Machine Learning Research, 3:993–1022.
Byrne, David, Goodhead, Robert, McMahon, Michael and Parle, Conor, (2023a), “The Central Bank Crystal Ball: Temporal information in monetary policy communication”, No 1/RT/23, Research Technical Papers, Central Bank of Ireland.
Byrne, David, Goodhead, Robert, McMahon, Michael and Parle, Conor, (2023b), “Measuring the Temporal Dimension of Text, An Application to Policymaker Speeches”, No 2/RT/23, Research Technical Papers, Central Bank of Ireland.
Chang, Angel X. and Manning, Christopher. (2012). SUTime: “A library for recognizing and normalizing time expressions”, In Proceedings of the Eighth International Conference on Language Resources and Evaluation (LREC’12), pages 3735–3740, Istanbul, Turkey. European Language Resources Association (ELRA).
Hansen, Stephen, and McMahon, Michael (2016), “Shocking language: Understanding the macroeconomic effects of central bank communication”, The Journal of International Economics, Volume 99, 2016, Pages S114-S133.
Hansen, Stephen, McMahon, Michael and Prat, Andrea (2018), “Transparency and Deliberation Within the FOMC: A Computational Linguistics Approach”, The Quarterly Journal of Economics, Volume 133, Issue 2, May 2018, Pages 801–870.
Istrefi, Klodiana, Odendahl, Florens and Sestieri, Giulia (2021), “Fed’s financial stability concerns and monetary policy” SUERF Policy Brief No. 80.
Nielsen, Finn Arup (2011), “A new ANEW: Evaluation of a word list for sentiment analysis in microblogs”, Proceedings of the ESWC2011 Workshop on ’Making Sense of Microposts’: Big things come in small packages (2011) 93-98.
Parle, Conor, (2022) “The financial market impact of ECB monetary policy press conferences — A text based approach,” European Journal of Political Economy, Elsevier, vol. 74(C).
Ramm, Anita, Friedrich, Annemarie, Loaciga, S. and Fraser, A. (2017), “Annotating tense, mood and voice for English, French and German”, Conference: Proceedings of ACL 2017, System Demonstrations.
Renault, Thomas. (2017). “Intraday online investor sentiment and return patterns in the US stock market”. Journal of Banking & Finance, 84:25–40.
Schmeling, Maik and Wagner, Christian (2019), “Does Central Bank Tone Move Asset Prices?,” CEPR Discussion Papers 13490, C.E.P.R. Discussion Papers.
Schumacher, Gijs, Martijn Schoonvelde, Denise Traber, Tanushree Dahiya, and Erik de Vries (2016), “EUSpeech: A New Dataset of EU Elite Speeches”, Technical Report.
Stone, Philip J., Dunphy, Dexter C., Smith, Marshall S., & Ogilvie, Daniel M. (1966). “The General Inquirer: A computer approach to content analysis in the behavioral sciences”, American Sociological Review 4(4).